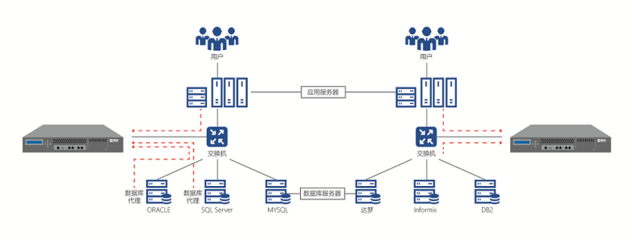
Greenplum数据库是一种基于PostgreSQL开源技术构建的大规模并行处理(MPP)数据仓库解决方案。其核心设计理念是通过分布式架构和并行计算来处理海量数据,特别适用于大数据分析和商业智能场景。Greenplum的系统架构是其高性能和高扩展性的基石,主要可以分为以下几个关键层次和组件。
1. 主节点(Master Node)
主节点是Greenplum集群的入口和控制中心。它不存储用户数据,主要负责接受客户端连接、解析SQL查询、制定并行执行计划、协调工作节点以及管理全局系统目录(元数据)。用户通过主节点提交查询,主节点将优化后的并行任务分发给各个工作节点,并汇总最终结果返回给客户端。为了高可用性,通常会部署一个备用主节点(Standby Master)。
2. 工作节点(Segment Node)
工作节点是实际存储和处理数据的核心单元。一个Greenplum集群包含多个工作节点(通常每个物理服务器部署多个Segment实例)。数据根据分布键(Distribution Key)被哈希分布到所有工作节点上,实现数据的并行加载和查询。每个工作节点运行一个独立的PostgreSQL实例,负责执行分配给它的那部分查询任务,并在需要时与其他节点进行数据交换(如广播、重分布)。
3. 互连网络(Interconnect)
互连网络是工作节点之间高速通信的底层网络。它是Greenplum并行查询执行的关键,负责在执行复杂查询(如多表关联)时,在不同工作节点间高效地传输中间结果数据。Greenplum使用基于UDP或TCP的专用网络协议(GNet)来实现低延迟、高吞吐量的节点间通信。
4. 存储架构
数据在工作节点上以堆表(Heap Table)或追加优化表(Append-Optimized Table)的形式存储。追加优化表针对批量数据加载和分析查询进行了优化,支持列式存储和压缩,非常适合数据仓库场景。数据分布策略(哈希分布、随机分布或复制分布)由用户定义,直接影响查询性能和数据均衡。
5. 并行查询执行
这是Greenplum架构的精华。查询计划被分解为多个切片(Slice),每个切片在工作节点的并行执行进程中运行。执行器(Executor)采用“移动”(Motion)操作符来实现节点间的数据流动,从而协同完成整个查询。这种“无共享”(Share-Nothing)的MPP架构使得系统可以通过增加工作节点来线性地扩展处理能力和存储容量。
6. 高可用与容错
Greenplum通过镜像(Mirror)机制实现数据高可用。每个主Segment可以配置一个或多个镜像Segment(位于不同的物理主机上)。当主Segment故障时,系统会自动切换到镜像Segment,保证服务连续性。主节点本身也可以通过备用主节点实现故障转移。
Greenplum数据库系统架构是一个经典且成熟的MPP设计。它将海量数据分散存储到大量低成本服务器节点上,并通过并行执行框架协同处理,从而实现了对PB级数据的快速分析。其与PostgreSQL的兼容性降低了学习与迁移成本,而分布式架构则赋予了它处理大数据时代复杂分析任务的强大能力。理解其架构层次与组件间的协作,是高效部署、运维和优化Greenplum数据库的关键。