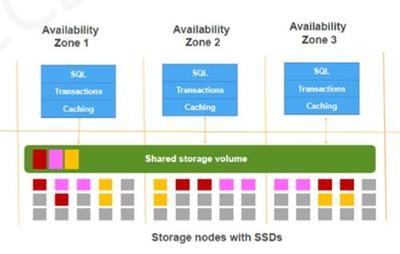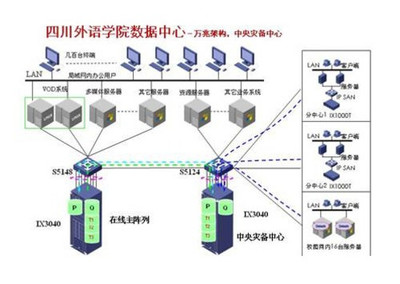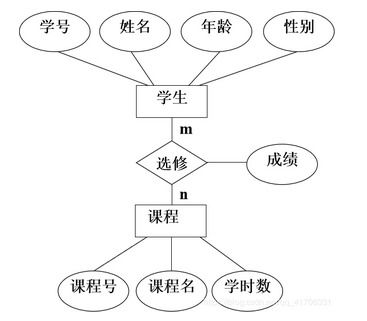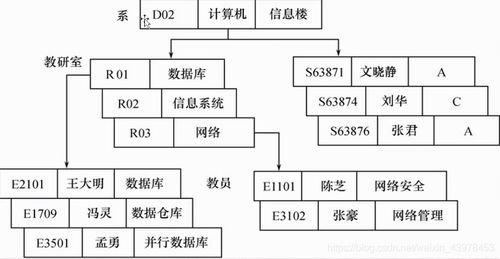
随着大数据和复杂关系分析需求的增长,图数据库因其高效处理关联数据的能力而备受关注。Nebula Graph 作为一款开源的分布式图数据库,以其高性能和可扩展性在业界广受认可。本文将深入探讨 Nebula Graph 的数据模型和系统架构设计,揭示其如何支撑复杂的图数据应用。
一、Nebula Graph 的数据模型
Nebula Graph 采用属性图模型作为其核心数据模型,该模型直观且灵活,适合表示实体及其之间的关系。其数据模型主要包括以下要素:
1. 点(Vertex):代表图中的实体,如用户、产品或地点。每个点具有唯一的标识符(VID)和一组属性(例如,用户的姓名、年龄)。
2. 边(Edge):表示点之间的关系,如“关注”或“购买”。边是有向的,并包含起始点、结束点、类型和属性(例如,关系的权重或时间戳)。
3. 标签(Tag):用于对点进行分类,每个点可以关联多个标签,每个标签定义了一组属性。例如,一个点可以同时有“用户”和“VIP”标签。
4. 边类型(Edge Type):定义边的语义,例如“朋友”或“交易”,允许在查询时过滤特定关系。
这种模型支持复杂的图遍历和模式匹配,使得 Nebula Graph 在社交网络、推荐系统和知识图谱等场景中表现优异。数据以图空间(Space)为单位进行组织,每个空间可独立管理,便于多租户部署。
二、Nebula Graph 的系统架构设计
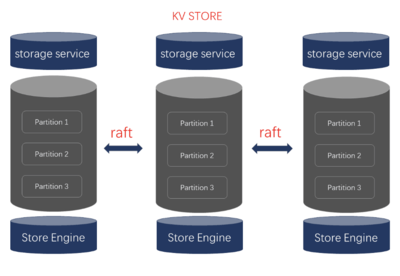
Nebula Graph 采用分布式架构,确保高可用性、可扩展性和低延迟。其系统架构主要由三个核心组件构成:
1. 元服务(Meta Service):负责集群管理和元数据存储,包括图空间、标签、边类型和分片信息的定义。它通过 Raft 协议实现一致性,确保元数据的可靠性和快速恢复。
2. 存储服务(Storage Service):处理图数据的持久化存储和查询。数据被水平分片(Partition)分布到多个存储节点上,每个分片通过多副本机制(基于 Raft)保证数据冗余和容错。存储引擎优化了图遍历操作,支持快速点边查询和属性过滤。
3. 查询引擎(Query Engine):负责解析和执行查询语言(nGQL),将用户请求转换为分布式任务。它通过计算下推(Push-down)优化,减少网络传输,并与存储服务协同处理复杂图算法,如最短路径或社区发现。
Nebula Graph 还包括图形化工具(如 Nebula Studio)和客户端 SDK,提升开发体验。整个架构支持线性扩展,用户可通过添加节点轻松应对数据增长。
Nebula Graph 的数据模型通过属性图简化了关系表示,而其分布式系统架构则确保了高性能和可靠性。这种设计使其成为处理大规模图数据的理想选择,适用于从实时分析到机器学习等多种应用场景。随着图数据库技术的演进,Nebula Graph 将继续推动数据智能的发展。