在数字化转型的浪潮中,数据已成为企业的核心资产,而数据库系统作为数据管理的基石,其性能、可靠性和扩展性至关重要。华为CloudNative分布式数据库技术是华为云在数据库领域的重要创新,它深度融合了云计算、分布式架构和原生云技术,旨在解决传统数据库在高并发、海量数据场景下的瓶颈问题。本文将深入解析华为CloudNative分布式数据库的关键技术、系统架构及其优势。
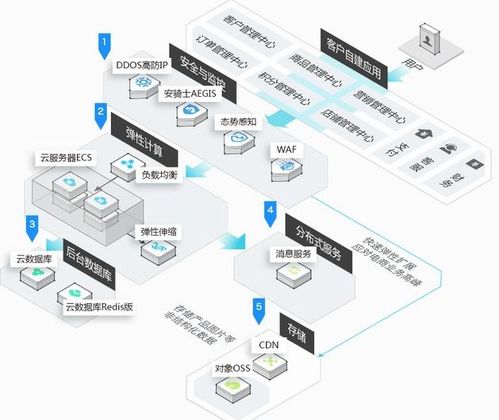
华为CloudNative分布式数据库的核心在于其云原生设计。它采用容器化和微服务架构,使数据库能够弹性伸缩,快速响应业务需求波动。通过Kubernetes等编排工具,数据库实例可以自动部署、扩缩容和故障恢复,显著提升了运维效率。这种设计不仅降低了硬件依赖,还支持跨可用区的多活部署,确保了高可用性和数据一致性。
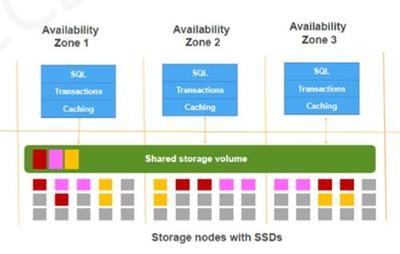
在分布式架构方面,华为数据库采用了分片(Sharding)和副本(Replication)技术。数据被水平分割到多个节点,每个节点独立处理查询,从而实现了负载均衡和高并发处理能力。同时,通过多副本机制,数据在多个节点间同步复制,即使某个节点故障,系统也能自动切换到备用副本,保证服务不中断。结合Paxos或Raft等一致性协议,华为数据库确保了分布式环境下的强一致性和事务完整性,满足金融、电商等对数据准确性要求严格的行业需求。
华为CloudNative分布式数据库优化了存储和计算分离的架构。计算层负责SQL解析、优化和执行,而存储层则专注于数据持久化和索引管理。这种分离设计允许计算资源根据负载动态调整,存储资源独立扩展,从而提高了整体资源利用率。华为还集成了AI驱动的智能优化功能,例如自动索引推荐和查询调优,进一步提升了数据库性能。
在安全性方面,华为数据库提供了多层防护机制,包括数据加密、访问控制和审计日志。通过TLS/SSL加密传输数据,结合角色基于访问控制(RBAC),确保只有授权用户才能访问敏感信息。同时,实时监控和日志分析功能帮助用户快速检测和响应潜在威胁,符合GDPR等数据保护法规。
华为CloudNative分布式数据库的优势体现在多个维度:高性能、高可用、弹性伸缩和成本效益。以华为云GaussDB为例,它在TPC-C基准测试中展现了卓越的事务处理能力,支持PB级数据存储,同时通过按需付费模式降低了企业总拥有成本(TCO)。实际应用中,该技术已广泛应用于金融、电信、互联网等行业,帮助企业在海量数据场景下实现业务创新。
华为CloudNative分布式数据库技术代表了数据库系统的未来发展方向。它不仅解决了传统集中式数据库的扩展性问题,还通过云原生和分布式创新,为企业提供了稳定、高效的数据管理解决方案。随着5G和AI技术的普及,华为将继续推动数据库技术的演进,助力全球企业实现数字化转型。