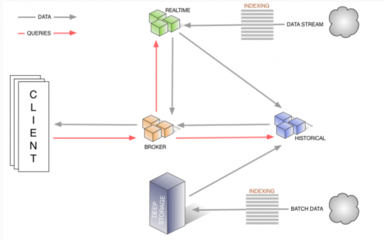
Druid是一款高性能、列式存储、实时分析的分布式数据库系统,广泛应用于大数据场景。本文将为您介绍Druid的核心概念、优势、应用场景及入门步骤,帮助您快速掌握这一强大工具。
一、Druid的核心特点
- 列式存储:Druid采用列式存储结构,查询时仅加载所需列,极大提升分析查询性能。
- 实时数据摄取:支持从Kafka、Hadoop等数据源实时摄入数据,实现秒级延迟。
- 分布式架构:具备高可用性和水平扩展能力,可轻松处理PB级数据。
- 时间序列优化:内置时间分区和索引,特别适合时间序列数据分析。
二、Druid的应用场景
Druid广泛应用于以下领域:
- 实时监控与告警系统
- 用户行为分析平台
- 物联网(IoT)数据处理
- 在线广告效果分析
其低延迟和高吞吐特性使其成为实时分析场景的首选。
三、入门操作步骤
- 环境准备:安装Java 8或以上版本,配置足够内存。
- 下载Druid:从Apache官网获取最新稳定版。
- 启动单机模式:运行bin/start-micro-quickstart命令体验基础功能。
- 数据摄入:通过控制台或JSON配置文件导入示例数据。
- 执行查询:使用Druid SQL或原生查询语言进行数据探索。
四、注意事项
- 生产环境需部署集群模式,配置ZooKeeper进行协调。
- 合理设计数据分段(Segment)策略以优化查询性能。
- 结合Apache Superset等工具可构建完整的数据可视化方案。
通过以上介绍,您已对Druid数据库系统有了基本了解。作为现代大数据生态的重要组成,Druid凭借其卓越的实时分析能力,正成为企业数据架构中不可或缺的一环。